If you take an interest in learning Morse code, you will quickly hear about “Koch method” and “Farnsworth method”. You will also read many opinions stated with absolute certainty, often contradicting each other. Some advice is straight out non-actionable.
I have recently read Koch Dissertation on Learning Morse Code. Yeah, I have unusual ways to spend my time. Anyway, the reason for this is that I wanted to actually understand what Koch actually claimed, and what he actually proved.
I start with a rant about reading a badly scanned German paper from almost 90 years ago, and a small digression about who Koch is, but you can directly skip to the main part of the article. Or directly to the conclusion.
The Rant
There is an English translation of the dissertation, but it is a machine-generated one. Although significant effort has been done to make it look nice, the content is often too mangled to be usable.
The only version I could find of Koch’s dissertation is an old scan. Although it was uploaded in 2020, the file was created in 2008. Unfortunately, this is a time when JBIG2 was a thing1. Sure enough, when extracting the images from the PDF, I see various files ending in “.jb2e” or “.jb2g”.
Internet Archive serves a text version of the document. Since the document was typewritten and not handwritten, the OCR actually did a pretty good job. However, since it was clearly OCR-ed after the conversion to JBIG2 took place, some characters are mixed up, in particular:
- h and b
- n and u
- c and e
Of course, most of the time, the resulting word did not make sense, and I just needed to fix the typo. In German. By the way, do you know about agglutination? Oh, and since it’s 1935, it uses various words that are obsolete today. Also, it’s orthography reform of 1996, so “ß” is still widely used. The OCR did not like that.
Thankfully, it’s 2023, and machine translation has removed all the borders, and made using foreign languages transparent. Or not.
Maybe it’s German, but neither DeepL nor Google Translate could make natural sentences out of the transcript. At least, they were mostly grammatically correct. But, between the fact that they still followed German word order and expressions, and the fact that they poorly cut sentences (sometimes duplicating them), it was far from a piece of cake.
Of course, after the transcription and the translation, we are not done. The argument itself is not a shining piece of literature. It was written by an engineer for a limited audience. On a deadline. And a typewriter.
Koch himself often repeats himself (in separate paragraphs, so it’s definitely not the machine translation), uses interminable sentences (the translation did not change the length), sometimes keeps the actual point implicit, and sometimes omits information altogether.
Extracting the gist of this paper was like peeling onions: each layer you remove only makes you cry harder.
Dr.-Ing. Ludwig Koch
Finding information about Ludwig Koch is not easy. It does not help that there were many other people named Ludwig Koch, including several doctors, and even a Prof. Dr. Ludwig Koch, born in 1850. And another teaching today. One thing to keep in mind is that our Koch was not a Doctor of Philosophy (PhD). His dissertation granted him the title of Doctor of Engineering, which would make him Dr.-Ing. Ludwig Koch.
What we do have to work with is the curriculum vitae attached to the end of the dissertation, where Koch states that he was born in 1901 in Kassel.
There was a “Dr-Ing. Koch” in the Nazi’s club2 of the technical university of Dresden in 1944, but it looks like it was Paul-August Koch, who studied textile and paper technology. The only other reference I have been able to find online of Morse-Koch is a 1971 document referring to “Dr.-Ing. Koch Ludwig”, which would match his title. He would have been 69 at the time.
Koch defended his thesis at the technical university Carolo-Wilhelmina. The main reporter was Prof. Dr. phil. Bernhard Herwig, who studied psychology3 and was mostly interested in studying working conditions for the good of the fatherland4. The co-reporter was Prof. Dr.-Ing. Leo Pungs, who was interested in more technical aspects of radio engineering as the dean of the Department of Electrical Engineering5. For the record, it looks like Prof. Dr. Phil. Bernhard Herwig was in the Nazi’s club, but Prof. Dr.-Ing. Leo Pungs was not6.
I tried to clarify whether Koch was actually interested in Morse code in and by itself, or was only using it as an arbitrary example to apply Arbeitspsychologie. He did have a degree in electrical engineering, but I found no evidence that he continued studying the learning of Morse code after he defended his thesis. In fact, there is no other trace of him in the academic record.
We think it was the same Koch famous for nature recordings
HackADay
No he’s not. Sound-recordist-Koch was born in 1881.
Koch was able to teach a class of students to copy code at 12 words per minute in under 14 hours. However, the method wasn’t often used until recently.
HackADay
I do not know why they think that “the method wasn’t often used until recently”. Koch’s method was known in the United States at least since The Learning of Radiotelegraphic Code in 1943.
Koch Dissertation
The bold parts are a summary of the summary I posted before. The rest are my comments.
For other summaries of the dissertation, look here, or here. I did my own summary independently of these, and before reading them.
We study how holism can help improve work conditions.
First, we need to tackle the fact that the dissertation is heavily oriented in favor of Gestalt psychology, or holism, which was very in at the time. Koch worked under the supervision of Prof. Dr. phil. Bernhard Herwig, who was mostly concerned with improving work productivity for the fatherland (see previous section), but it does not look like he was particularly focused on holism. This point would require more investigation, but my understanding is that Koch was somewhat biased towards holism due to the historical context, but not overtly.
When experienced radio operator send Morse code at a speed lower than 10wpm, the resulting timings are distorted
However, this was done with only 4 subjects. They do show the same overall pattern, but there are significant differences between them. So, it is hard to conclude with anything as precise as a “10 wpm threshold”. The associated graphs would tend to show that the distortion is still very visible even at 16 wpm (80 chars/min). The main point stands, but the point where sending is slow is very debatable.
Experienced radio operators have difficulty receiving Morse code at lower speed
This is associated with the graph below. Again, the main point is pretty clear. The accuracy of reception falls off a cliff as the speed decreases. However, the speed where this happen is again debatable. 90 % is already a pretty accuracy for an experienced operator. That’s one error every tenth character!

If we look more closely at the graph, we notice that the curves bend downwards somewhere above 10 wpm. And if we pay attention, we notice that there are actually very few data points from which the curves are drawn. There is not enough information to know when the accuracy falls below 95 %, for example. There might be multiple data points in the upper right corner, but it’s hard to tell without the raw data, which is not available.
In short, slow speed is terrible, but there is no clear evidence that 10 wpm and above should be considered good enough.
- Naive: first, learn all the characters at a slow speed, then increase the speed
- Farnsworth7: first learn all the characters at a high speed, but with ample spacing, then decrease the spacing, then increase the speed
- Koch: first learn the rhythm at 12 wpm, then learn 2 characters, then add other characters one at a time and finally increase the speed
Because this matches my intuition, I would like to say that the previous experiences show that the naive approach is clearly mistaken. But, looking at it objectively, it’s not what the experiences show. What they do show is that using low-speed Morse is not strictly easier than using high-speed Morse, to the extent that experienced operators do not automatically master low-speed Morse.
The main point of Koch can be summed up in two statements:
- At lower speeds, we need to think, while higher speeds rely on automatic recognition
- Starting to practice Morse with the thinking-mode is a waste of time
Regarding statement 1, it is hard to find explicit evidence, but it is at least sound, from the fact that operators just do not have the time to think about each individual dit and dah at high speed. However, this does not preclude the possibility of progressing to automatic recognition at lower speed. Also, at higher-speed, it is definitely possible to think about what you hear, just on a more selective basis.
For statement 2, I want to highlight the fact that the thinking- and automatic- modes directly map to the cognitive and autonomous stages in Fitts and Posner’s model. Thus, there is nothing inherently unnatural in progressing from thinking-mode to automatic-mode. The harsh plateau when switch from the former to the latter might just be a requisite passage in the learning process8.
In this part, the arguments of Koch for statement 2 are not supported (nor invalidated) by evidence. The evidence comes later in the paper from comparing Koch method with the other procedures.
Harder characters (X, Y, P, Q) should not be learned at the very first. Koch uses L, F, C, K, R, P, X, Y, Q, D, B, G, A, N, Z, U, V, W, J, H, S, I, E, O, M, T.
That makes sense, at least to avoid frustration. As far as I know, Koch did not systematically investigate the learning order, so that’s a minor point.
Same for similar characters (E/S/H/5, U/V, D/B, G/6, W/J)
Same as above.
Training sessions should be spread out in time instead of packed together, and should not exceed half an hour.
Spoiler: this is the truest claim of the paper. But it is not surprising. The spacing effect has been known from even before Koch was born. In fact, Koch cites a paper from 1897 on this exact topic.
The experience was conducted with students, tradesmen and businesswomen with two or three sessions a week, so it was at a disadvantage relatively to military training
As one knows, psychology is the study of psychology students. To be fair, Koch states that it was not just students. But, since we do not have the raw data, we cannot tell whether it was 10 % students, or 90 % students.
In any case, this argument is kind of weird. Koch argues that his study was biased in a way that should have made good results harder with relation to military training. Morse code training is offered to anyone who joined the military, while student are a select class of individuals, especially at the time.
In addition, he just argued that short sessions spread out in time were more effective than long, packed sessions (like the military does).
Two-tone method: using different tones for the dits and dahs helps at the start of the training
This is an idea that I see very rarely when I read about the Koch method online. Actually, I think the only instance is at LICW. I find it very appealing, since it sounds like it could really help with recognizing the characters more easily at first, and thus improve the feedback loop for learning.
However, the evidence for its effectiveness provided in Koch dissertation is very weak.

The argument is that the two-tone curve is always above the one-tone curve. However, there are a number of issues:
- We do not know how many participants there were in each case, so we cannot assess the significance of the result
- The curve have lots of variations, which suggest random differences were not smoothed out by the law of averages
- The relation between the two curves do not show a continuous advantage, since the spread does not increase over time. In fact, they even merge for a time!
- Even if we ignore the fact that they merge, the spread is mostly set during the second half-hour. We expect to see the most variance at the beginning of the training, when students are not familiarized with the process, and differ in their learning patterns. So it might explain the spread entirely.
Again, the two-tone method could actually be useful, but we cannot tell from the evidence. If anything, we do learn that the advantage is marginal at best.
In fact, LICW did try the two-tone method, but they found no advantage:
we experimented with introducing two-tone characters to new students and the feedback was overwhelmingly negative
Long Island CW club
The characters were added as H, F, A, B, G, C, D, E, CH, L, K, I, O, T, M, P, Q, R, S, N, U, W, V, Y, X, Z (no J)
With the new methods, students take 14 hours to master Morse code, instead of 10 weeks
This is definitely the most important claim of the paper. Military training typically uses several hours every day for months on end. Reducing this to only 14 hours, every if spread over several weeks, is phenomenal.
Well, 14 hours with 3 half-hour sessions a week is still about 10 weeks. So the whole gain would be about spreading the sessions instead of packing them. But still, let’s say that the claim is that this is only made possible thanks to the new method.
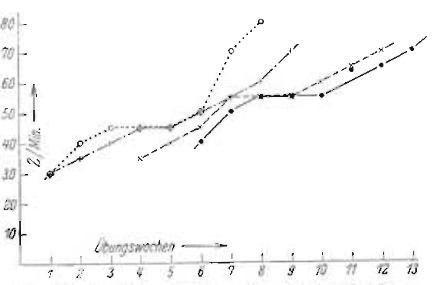
This is supported by the two following graphs9.


Alas, there are a number of confounding factors that are not addressed.
One. In the second graph, we can see that the training completed once students had mastered the 26 letters of the alphabet. This excludes digits, punctuations, which are necessary for normal operation. But the first graph is actually not based on Koch experiments. It was “kindly provided by the Deutsche Verkehrsfliegerschule”, a military-training institution. Of course, we have no more information, so we do not know how many characters they had to learn.
In comparison, it took me less than 20 hours to reach 26 mastered characters (lesson 25 at LCWO) at 20 wpm, but 35 more to master all LCWO lessons. I did follow the Koch method, in the fact that I trained at 20 wpm from the get-go, without extra spacing. But the point is that, at 26 characters, I was still very far from being done.
Of course, the first graph could be about learning only the 26 letters, but it’s never stated so, and we have no way to check.
Two. The target speed is set to 12 wpm, which is actually pretty low. Koch himself states that the passing speed is usually at 20 wpm:
Radio communication in the ship service is under the same conditions, i.e. perfect mastery of Morse code at 100 char/min.. The examination conditions of the radio operator course are, for example:
“Keying a telegram of 100 words of 5 letters each in 5 minutes on the Morse apparatus in perfect form. Receiving a code telegram of 100 words and an open text of 125 words of 5 letters each in 6 minutes; transcribing the latter on the typewriter.”
Koch claims that going from 12 wpm to 20 wpm would be relatively easy, since all the characters have been learned in the automatic-mode. However, this was never tested, so there is no concrete evidence showing this. As an illustration, I took 55 hours to master 20 wpm (with 41 characters), but I am barely reaching 28 wpm 30 hours later.
Three. Remember how, in the previous quote, it said “perfect form”? Koch sets the bar at “less than 10% error rate”. It took me 44 hours to reach lesson 40 of LCWO at 10 % error rate, but still 11 more hours to get it down under 5 %.
And now, for the most damning issue.
Aptitude test: those who fail to master 4 characters at a speed of 60 char/min in the first 2 half-hours never mastered all characters.
This could indeed be a useful aptitude test. However, it points to a fundamental flaw with the study. What does it mean by “never”?
Does Koch mean that these students were allowed to continue the practice for months until he wrote his dissertation? And, more importantly, that he took their learning time in the above graph?
Or does it mean that they were allowed to continue the practice until the 28th session? In that case, it should show as a value strictly lower than 26 for the number of mastered letter at the end of the experience.
Or does it mean that they were removed from the experience early, when they gave up, or when it became clear that they could not keep up?
In any case, this is never addressed in the paper. Yes, military trainings eliminate students aggressively as they fall behind. And it could even be that Koch had a much higher success rate. But we do not know. At all.
Conclusion
Koch brings interesting ideas. However, none are supported by the evidence he brings forth. Except one, which is to use spaced repetition. This one is actually well-known and supported by evidence. Koch himself recognizes this.
To stress the point: it is very well possible that some parts of this method actually have a positive impact, but we do not have enough evidence from this paper to conclude. I have read many times people say that using Koch method, or Farnsworth method, or whatever method helped them. But, until we have concrete evidence, we cannot conclude that one approach is better than the others.
Then, how should I learn Morse code?
Just use Koch method on LCWO at 20 wpm. Lower if it is too fast. Practice 10 minutes a day. Every day. And keep at it.
But you just said that Koch method was not supported by evidence!
Yup. But it is not disproven either, and no other method is proven to work better10. Don’t get stuck in analysis paralysis trying to find the one best method. Use Koch because it’s the one for which there are the most tools, including LCWO, the most convenient one. Or just because I said so. Use 20 wpm because that’s the default in various places. Or because that’s what I did. But don’t worry about lowering it if you really cannot manage.
What does matter is actually practicing. So spaced repetition and discipline.
How long does it take to learn Morse Code?
Count 50 to 100 hours if you want to be comfortable at 20 wpm. Count a minimum of 10 to 20 hours for the bare basics if you’re aiming for 12 wpm.
This is a personal question but on average students get on the air doing their first QSO in 3-4 months.
We do not have requirements but recommend as a minimum 2 classes per week and 15–20 minutes daily practice.
FAQ of Long Island CW Club
We teach the code at 12 words per minute. This speed was determined by Koch to be optimum for initial learning of CW. It is also optimum for making first contacts on the air.
Description of Morse code training at Long Island CW Club
Should I learn the Visual Representation?
Sure, if you find it fun. It’s a pretty easy goal, and that could be quite enough if you want to shine in escape games. If you intend to actually use it over the air, don’t wait until you have learned it, and just start practicing what you actually want to do.
Should I Learn Mnemonics?
No. Seriously, they’re all terrible, and it’s not that hard to learn the 26 letters, even if it’s just for an escape game.
- JBIG2 is a “clever” image compression format in that it notices when two parts of the image looks similar, and only store one. So, if two characters look a bit similar in a document scan, it could decide to merge them, making them identical. This obviously did not go well. ↩︎
- Dresden 1944–1945 program, page 31 of the document, page 33 of the document (note: “NSD” stands for “Nationalsozialisticher Deutscher Dozentenbund”) ↩︎
- Carolo-Wilhelmina 1929–1930 program, page 13 of the document, page 12 of the PDF, left half ↩︎
- Braunschweig during the National Socialism, pages 118–134 ↩︎
- Carolo-Wilhelmina 1929–1930 program, page 8 of the document, page 10 of the PDF, left half ↩︎
- School year 1944–1945 program, pages 21, 22 of the document, page 15 of the PDF, right half and page 16, left half ↩︎
- It was only named “Farnsworth method” much later though, as analyzed by the Long Island CW Club ↩︎
- I do not claim this is the case. But, so far in the paper, we have no evidence either way. ↩︎
- Koch also refers to another study, Methoden der Wirtschaftspsychologie (Handbuch der biologischen Arbeitsmethoden, page 333) which have a graph similar to the first one. However, the plateau is described has happening at 14 wpm, not 12 wpm. It also goes up to 22 wpm for reception, not merely 16 wpm. ↩︎
- Again, based on Koch’s dissertation. Other research might actually prove that one method works better. I have just not read one yet. ↩︎