tl;dr: I do not like merging the main branch into feature branches, and I do not like squashing MR/PRs
git commit
git has emerged as the obvious choice for SCCS (Source Code Control System). The consensus is that it is unambiguously better than the previous standard, SVN. There is some debate as to what is the current best SCCS, especially regarding the confusing command-line interface of git1, but the first mover effect gave the advantage to git, and network effects make the space a winner-take-all situation.
However, we are not here to discuss this, which is a settled issue in practice (just use git). Instead, I want to talk about another debate, which is still far from being settled. I want to talk about what happens when you want to merge a PR (pull request, in GitHub vernacular) or MR (merge request, at GitLab).
git merge
Okay, let’s say we have the typical situation represented in the graph below.

In git parlance, we want to merge the feature branch into the main branch. This way, the changes from the feature branch will also be present in the main branch. Conceptually, this looks like this:

This is pretty and intellectually satisfying, but this hides the complexity that makes things hairy in practice. When merging the branch, there might be conflict: there could be changes in the main branch and in the feature branch that affect the same portion of the code.
git won’t always know how to resolve that automatically. You can do the manual resolution in GitHub or GitLab, but it is usually more comfortable to do it locally from the comfort of your IDE2. In general, that means you merge the main branch into the feature branch, push the updated feature branch, and get it merged into the main branch. This looks like this:

But that’s still mostly fine. And we could probably make it so that we only have one merge commit. But the practice of merging the main branch into the feature branch is opening the floodgates for git history messes. Because merge conflicts are painful, you’ll want to resolve them often. And you might have a long-lived branch that you keep having to make ready for merging, until you realize you need more changes. And so:

And that’s just a single branch. When you apply this madness to a project where multiple developers are actively contributing, this is what your history becomes:

git bisect
Let’s take a step back. Why are keeping all this stuff in the git history. Does the fact that we resolved conflicts really needs to be remembered for posterity? What do we actually want there?
What really matters is the final state of the code. We might need to keep the code of each previous released version in case we need to backport a fix. But we do not need all the little changes in between for that.
git history gives you too things.
First, you can check in what context the little change was made. If you are unsure what a piece of code is there, just use git blame to find the commit which added it3.
Second, you can test with any intermediate version of your software. Oh, a bug was introduced between version 2.17.6 and version 2.18.0? Instead of comparing the full diff between these versions, just find at which commit the bugs appears. And if your history is clean enough, you should be able to git bisect to find that commit in logarithmic time.
And that second one is really a magical power. Understanding a bug is much easier when you are looking at a 10-line diff than when you have basically the whole codebase as a suspect.
And guess what, merge commits are useless for either of these. Worse, if the offending commit is a merge commit, you will have to understand the conflicts it was trying to resolve. And if there is a bug here, it probably means the conflict was not trivial. Oh, and looking at the diff of the merge commit by itself is useless, so you will need to read potentially multiple commits from the two branches it brings together.
Thankfully, we can avoid all this.
git rebase
What we really want to keep is the changes that were brought by the feature branch. So why not do just that? Just reproduce the changes on top of the main branch. You will still have conflicts, but you will resolve them by updating the feature commits, instead of adding a merge commit.

The nice thing about this is that the individual rebased commits still make sense. Just by looking at their diff, you can tell what they are doing. With a merge commits, this can be more difficult.
git squash
There is one more thing. Once you have rebased, you can keep it as it, or you might make some more changes.
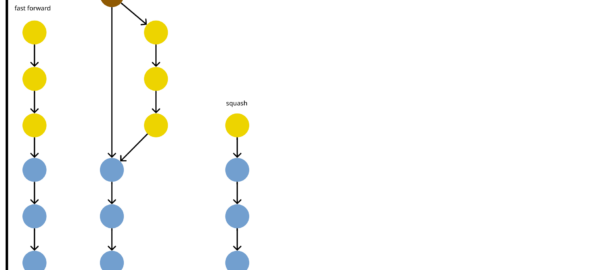
- fast-forward: always rebase the branches, even if there are no conflicts, to keep a purely linear history; this gives you a very nice history, but you lose the MR/PR as a unit, which can be useful for context
- merge-commit: add a merge commit, whether it is necessary (even without conflict, two branches might not be built upon one another) or not; this gives you most of the advantages of rebasing, but you also keep track of the MR/PR (e.g. a link in the merge commit)
- squash: combine all the commits of the branch into a single once; so no merge commit and a purely linear history, and you can keep track of the MR/PRs (in the squash commits), but you lose the intermediate commits

My personal projects are usually fast-forward, since I do not bother with PR/MRs. However, for projects with collaboration, I actually prefer merge commits after rebasing.
To finish, merge commits after rebasing have the nice side effect that git branch --merged still work. That lets you clean up your local branches once your PR/MRs are merged into the main branch. squash commits modify your branch on GitHub/GitLab, making them different from your local ones, and fast-forwarding might rebase your branch even after you solved conflicts.
- I won’t dispute that the command-line interface of git makes little sense, but I think this is overblown. As a beginner, the few commands you need are mostly straightforward. The intermediary phase is a bit more painful as you learn the various different effects of
git reset. However, this is a temporary state, and you quickly reach a point you use git seamlessly. ↩︎ - Vim ↩︎
- Of course, if git blame just finds a reformatting commit, or a commit which merely moved the code, you will need to git blame again, until you find the commit that actually interests you. ↩︎

Leave a Reply