tl;dr: When you think about it, hashing password only client-side (in the browser, in JavaScript) is not as terrible as you might think. And if you do most of the work client-side, you get something that is actually pretty secure.
Storing Passwords
So, I have been working on modernizing a Web application and fixing some of its issues. As someone who has spent way too much time implementing cryptographic primitives and cracking password hashes for fun, one of the main problems was that passwords were only hashed client-side.
For the context, we have learned quite a long time ago that storing raw passwords in a database was a bad idea. If the database leaked, all passwords were immediately compromised. Since people tend to reuse the same passwords for various services, it meant that compromising a non-sensitive service would allow an attacker to access very sensitive accounts of many individuals.
So we encrypt them. Except we don’t. If the database leaks, the encryption key will probably leak as well. Instead, we cryptographically hash the password. That is, we transform them in something completely different, irreversibly. So, “correct horse battery staple” would become “c4bbcb1fbec99d65bf59d85c8cb62ee2db963f0fe106f483d9afa73bd4e39a8a”.

Because the same password always get hashed the same way, we can authenticate people by comparing the hashes instead of the passwords themselves. No need to remember the password in the database! And if the database leaks, no attacker cannot find “correct horse battery staple” from “c4bbcb1fbec99d65bf59d85c8cb62ee2db963f0fe106f483d9afa73bd4e39a8a”.
Well, except they can.
Slowing down attackers
Although cryptographic hashes are designed to be hard to directly reversed, an attacker who got access to the hashes can just take a guess, hash it, and check whether it matches the hash of a user. If it does, it has found a password.
Since cryptographic hashes are also designed to be very fast, an attacker can try many guesses in a short amount of time.
The average password entropy is 40 bits. The median is likely to be lower. A modern CPU can compute more than 1 million SHA-256 hash computation per seconds. So trying every password with 40 bits of entropy would take less than 2 weeks.

Thankfully, we can make things more difficult for the attacker. What if, instead of storing SHA-256(password), we stored SHA-256(SHA-256(password)). It would make things twice as hard for the attacker, and would not change much when we validate a user’s password for authentication. We can go further! Instead of requiring to compute SHA-256 twice, we can make it so that it takes ten, a hundred, a thousand iterations! We can choose a number that makes it so that hashing the password takes 10 ms on the server. In that case, it would take the attacker 350 years of CPU time! This is basically PBKDF2.

Except that the attacker can do something that we cannot: it can try many guesses in parallel. Today’s CPUs can have dozens of cores. GPUs scale even more. And, with Bitcoin/blockchain/web3/NFTs, people have started building dedicated hardware to hash SHA-256 en masse. For a few thousand dollars, you can get hardware to crack SHA-256 at tens of billions of guesses per second. Even with our clever scheme, the attacker is back to 2 weeks to try every password1.
That’s cheating!
Yeah, it is! But we can do something about that. GPUs and dedicated hardware are designed for very specific tasks. We can take advantage of that to make it very hard to crack passwords with them. The trick is to replace SHA-256 with a hash function that requires a lot of memory to compute. It turns out, people have designed a very good one! Argon2id2
That’s basically the state of the art in storing passwords3.
Client-Side Only Hashing

Now, that’s quite a bit of work for our server. We need to do a significant amount of computation every time a user tries to connect. What if we had the user’s client do it instead?
Instead of sending the password, and having the server hash it, let’s imagine we use some JavaScript to hash the user’s password with Argon2id, and then send it over the network. Now, the server only needs to compare the hash to the one in the database!

There is one issue though: from the point of view of our Web application, the actual credential is not the password anymore, but the hash. So if an attacker gets the hash, they can authenticate as the user. In other words, a database leak means the credentials leak!
It’s not as bad as in the initial scenario, however. These credentials are only valid for our service. And it is still very hard to find the original passwords from the hashes.
Mostly Client-Side Hashing
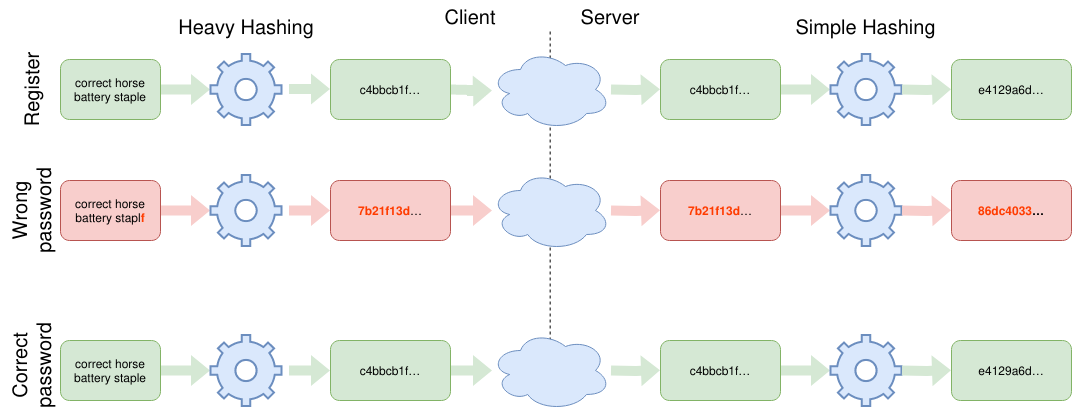
We can improve this with a simple observation: since it is very hard to get the password back from the hash, we can treat the hash like a high-entropy password.

In this case, brute-force attacks become irrelevant, and we do not need to iterate or use memory-hard functions. Instead, we could just use a fast hash. It looks like that:
- The browser computes an intermediate hash with a slow memory-hard function
- The browser sends the intermediate hash to the server
- The server hashes the intermediate hash with a fast function, getting the final hash
- The server compares the final hash with the one in the database
From the point of view of the server, the effective credential is the intermediate hash. However, if the database leak, the attacker only gets the final hash. It would be very hard to find the intermediate hash directly from the final hash, since the input space is very large. And it would be very hard to find the user’s password from the final hash, since a memory-hard function is involved.
The nice thing is that all the heavy work is offloaded to the browser, while still keeping the password secure!
The one drawback that I can think of is that this is not enforced by the back-end. If the front-end (especially a third party one) does not do proper memory-hard hashing, passwords might become exposed.
A positive side effect is that the back-end never sees raw passwords. It can be a good mitigation for inadvertently leaking information in the logs. Leaking the intermediate hash still allows an attacker to authenticate as a user, but they are not able to get their raw password and compromise the user’s accounts on other websites.
Conclusion
A priori, client-side hashing is a terrible idea from the point of view of security. However, looking more closely at it, it looks like it can actually make sense. But we should still use hashing on the server to avoid any risk of leaking credentials.

Leave a Reply