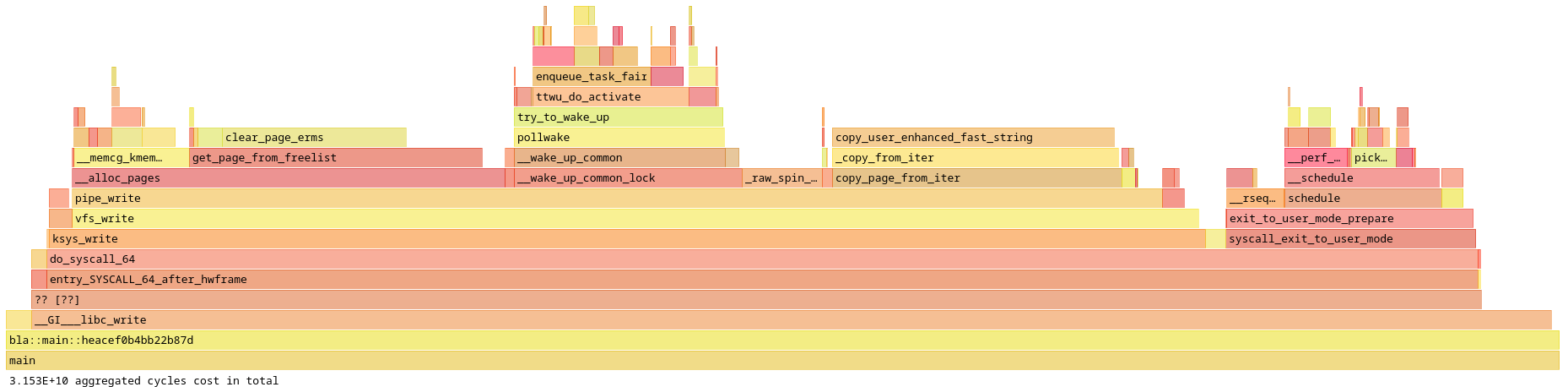
In my latest article, I made heavy use of flamegraphs. To makes things clearer, flamegraphs are visualizations of how much time is spent in each function in a program:
The interactive part is what lets you click on a function to focus on its call stack. If this is too small, look at the bottom of the article for a wider version.
In this article, we’ll see how to collect the necessary data, how to generate an interactive SVG to display that data, and how to integrate that SVG in WordPress.
Setup
First, you’ll need to enable event reporting from the kernel by using:
echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid
You will also want to make sure to compile the program you are profiling with the debug symbols, to identify the functions easily1:
The pipe seems to confuse it, so we explicitly need to add -o perf.data to make it work as expected. If you forget that, you will get this error message:
setting the pipe size failed, are you piping the output somewhere? error: Bad file descriptor
So far, we were on the most traveled path, using neatly prepacked programs. For this step, we’ll need to download and run some Perl scripts. In our case, we are interested in stackcollapse-perf.pl and flamegraph.pl. The first one parses the output of perf, and the second one outputs the interactive SVG. Assuming your profiling data is named perf.data, you would use:
The --height=24 argument is not necessary, but it does make things a bit more readable.
You can add a title and a subtitle with the corresponding --title="Some title" and --subtitle="Some subtitle" arguments. Note that the text is embedded as-is in the XML of the SVG, so you will need to escape any angle brackets (< and >) as < and >.
Embedded the SVGs in WordPress Articles
If you try to insert the resulting SVG file in a WordPress article2, you will only get a static image because any JavaScript code is stripped for security. Since we do want to keep the JavaScript code in this instance, we’ll have to use a Custom HTML block3.
However, there is still a catch. The JavaScript code contains opening angle brackets (<). In XML, that would be interpreted as an opening tag, making the SVG invalid. To avoid this, the whole JavaScript code is in a CDATA section:
…
</style>
<script type="text/ecmascript">
<![CDATA[
// JavaScript code that can freely use < and &
]]>
</script><rect x="0.0" y="0" width="1200.0" height="310.0" fill="url(#background)" />
…
Unfortunately, WordPress mangles this. So, we need to remove the <![CDATA[ and ]]> markers (do this directly in the script instead of editing each SVG file). This breaks the SVG for other readers (including opening the SVG file directly in Firefox), but, unfortunately, we cannot do much about it.4
I did try to use the old <!-- and --> trick from the early Web, but this is still interpreted as a comment in XML, so this makes the image mostly static. ↩︎